Machine learning might feel like magic when it works, but let’s face it, not every spell hits its mark. Sometimes your model knows too much for its own good. It masters the training set like an overachieving student who memorizes the textbook cover to cover. But the moment it faces a new test, it crumbles. That’s overfitting in machine learning for you.
Related: What is Machine Learning? – Supervised & Unsupervised
What is Overfitting in Machine Learning?
Overfitting in machine learning happens when your model focuses too much on the details of the training data.
Instead of learning the broader trends or patterns, it memorizes irrelevant details, including the irrelevant noise. Noise refers to random variations in the dataset that do not provide useful information. It can mask the actual structure of the data and make it harder for models to perform well on new, unseen inputs.
When a model overfits, its performance looks great during training but falls apart when tested on validation or test datasets.
Overfitting in machine learning can be identified by two key signs:
- Very low error on the training data.
- High error on the test or validation data.
Understanding Overfitting with an Example
Let’s consider a simple dataset where you have one feature, X, and you want to predict Y.
Imagine plotting the data points and noticing an upward trend that levels off at some point.
In this scenario, a good model would capture the overall trend of the data without being distracted by minor fluctuations. It would produce a smooth line that predicts the general relationship between X and Y.
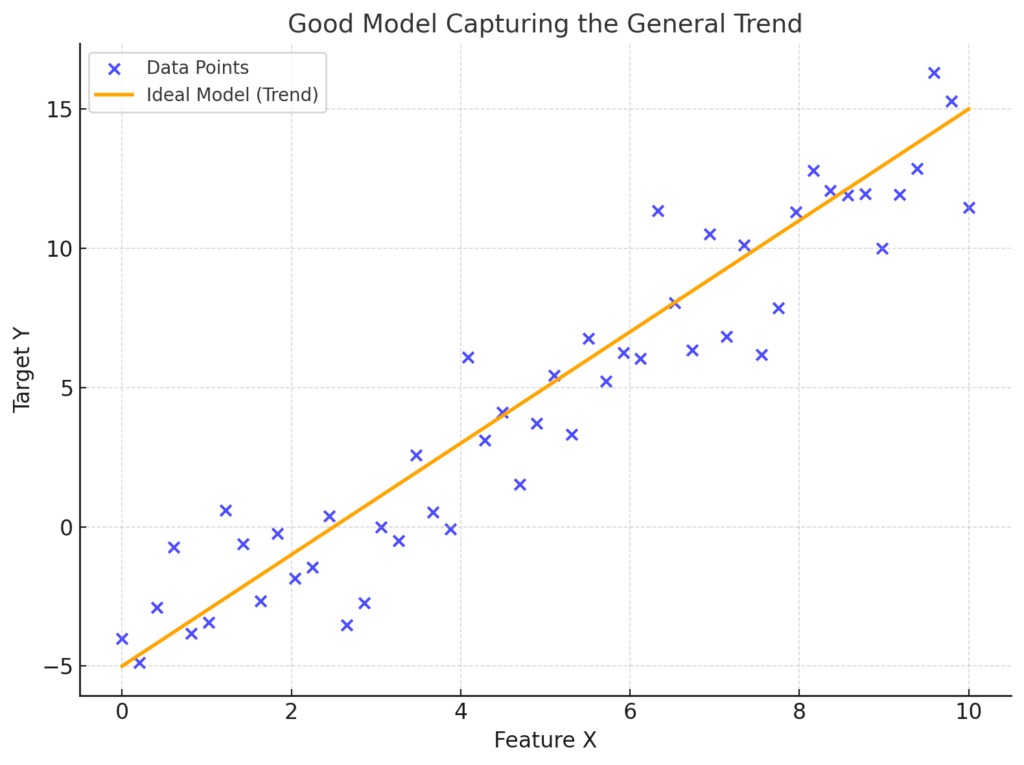
This visualization represents an ideal scenario where the model captures the overall trend without being influenced by minor noise. The scatter points represent the actual data, while the orange line shows the smooth prediction by our ideal model.
Now let’s see what happens when the model overfits.
Instead of following the broader trend, it zigzags around to match every single data point in the training set. This overfitted model hits all the training points perfectly but struggles when tested on new data.
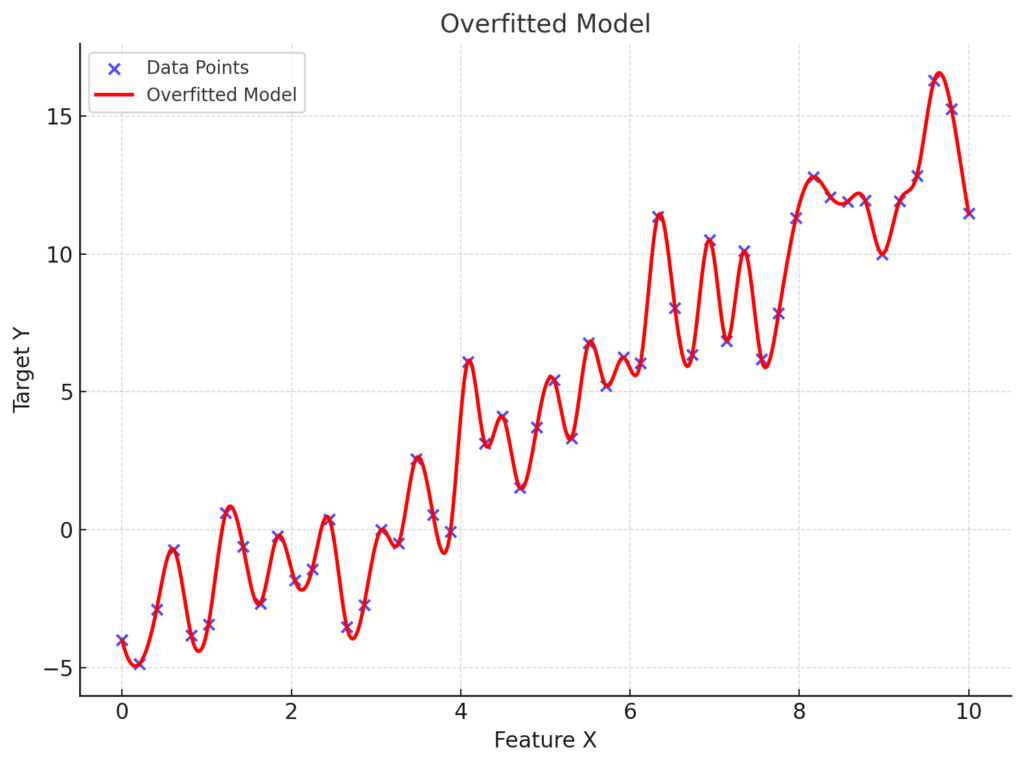
Now let’s look at a chart that highlights how an overfitted model struggles when faced with a new test point, shown in green:
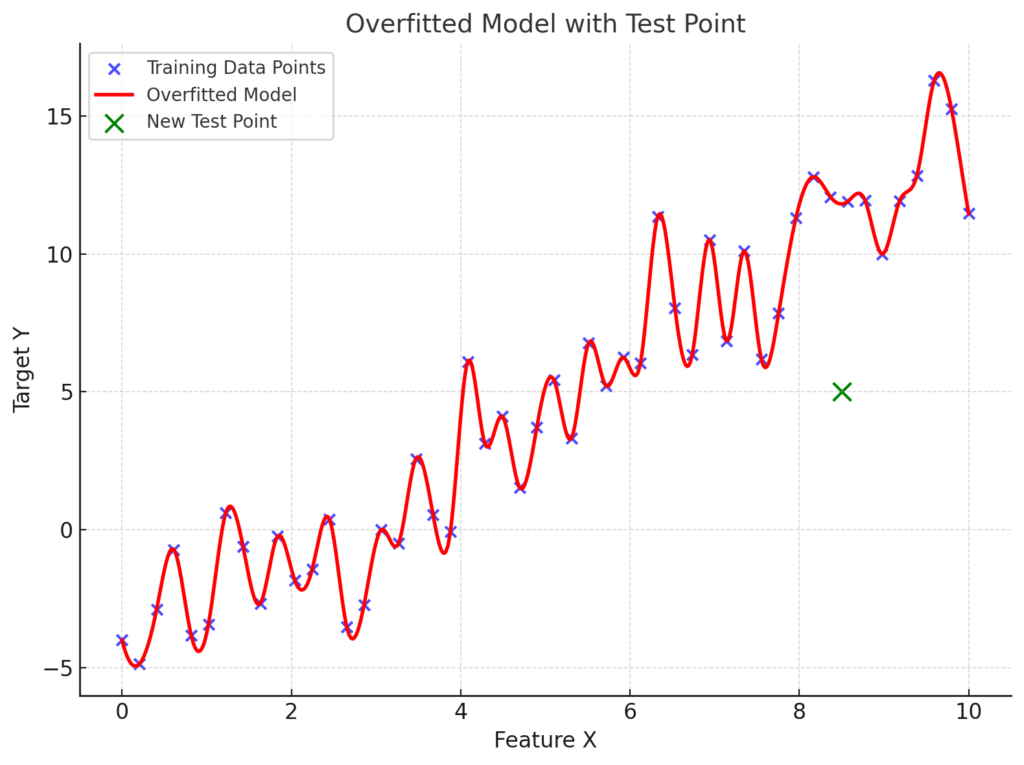
The overfitted model fails to generalize well and cannot accurately predict the value for the unseen test data, even though it perfectly fits the training data.
Read: KNN Algorithm Using Scikit-Learn – Classifying Iris Species (Tutorial)
Underfitting in Machine Learning
The polar opposite of overfitting in machine learning is underfitting.
Instead of trying too hard to capture every detail of the training data, an underfitting model doesn’t try hard enough. It fails to grasp the underlying trends and relationships in the data, leading to poor performance.
What Is Underfitting in Machine Learning?
Underfitting occurs when the model does not learn enough from the training data.
It fails to grasp the general trend and as a result, cannot represent the data accurately. This issue often arises when the model has high bias and low variance.
High bias means the model is consistently wrong because it oversimplifies the problem. And, low variance means it does not react to fluctuations in the data. The combination leads to a model that performs poorly on both training and test data.
Understanding Underfitting with an Example
Imagine our previous dataset or the diagram where we had a single feature X and a label Y.
A good model would properly fit the trend in the data nicely.
However an underfitting model would fail to do so. It might draw a straight line through the data, completely ignoring the variations and patterns.
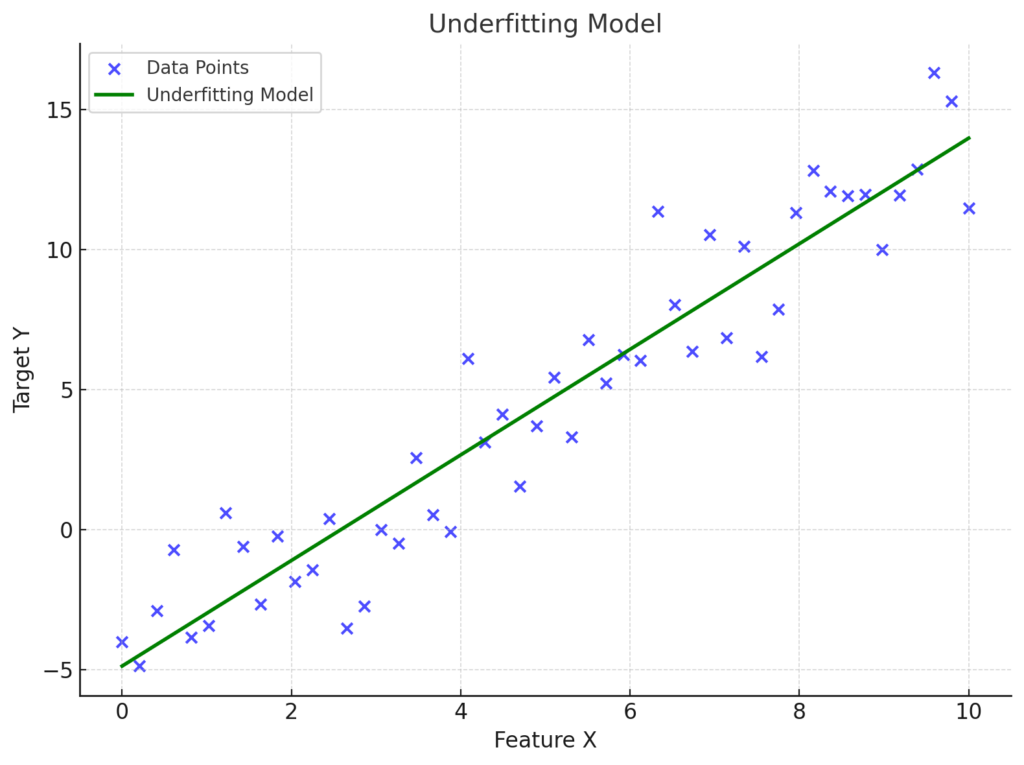
Our chart here illustrates an underfitting model, represented by the green line.
This model fails to capture the variations and patterns in the data, and gives us an overly simplistic straight line. Moreover this chart also demonstrates how underfitting in machine learning leads to poor performance by ignoring the true relationships in the dataset.
While this is easy to spot in one-dimensional data, it becomes challenging with complex datasets.
Tracking Model Performance Over Training Time
In more complex scenarios, we can analyze the behavior of the model’s error over training time. As a result, it helps us to identify underfitting and overfitting in machine learning.
Behavior of a Good Model
A good model starts with a high error when it first encounters the training data. Over time, the model learns and adjusts its internal parameters, reducing the error. Eventually, the error stabilizes, reaching a minimum value. This pattern shows that the model is learning effectively.
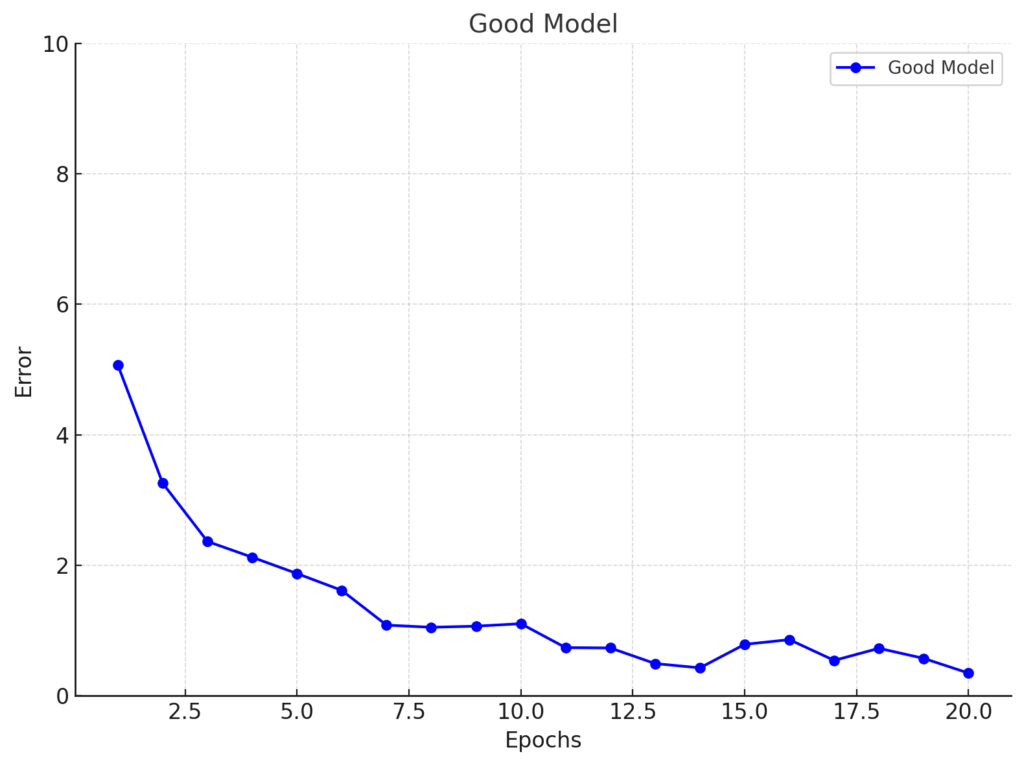
We can see that, initially, the error is high. It’s because the model has not yet learned from the training data.
Over time, the error decreases and stabilizes, reaching a minimum value, indicating effective learning and adjustment of the model’s internal parameters.
In machine learning, the term epoch refers to one full pass through the training data.
With each epoch, the model learns and improves its performance. If you see a gradual decline in errors over time, it indicates a well-trained model.
Behavior of a Bad Model
Now, what happens to errors over time with bad model? Or when there is overfitting or underfitting? How does that look?
Well, bad models behave differently. In the case of overfitting, the training error decreases steadily, but the test error begins to rise.
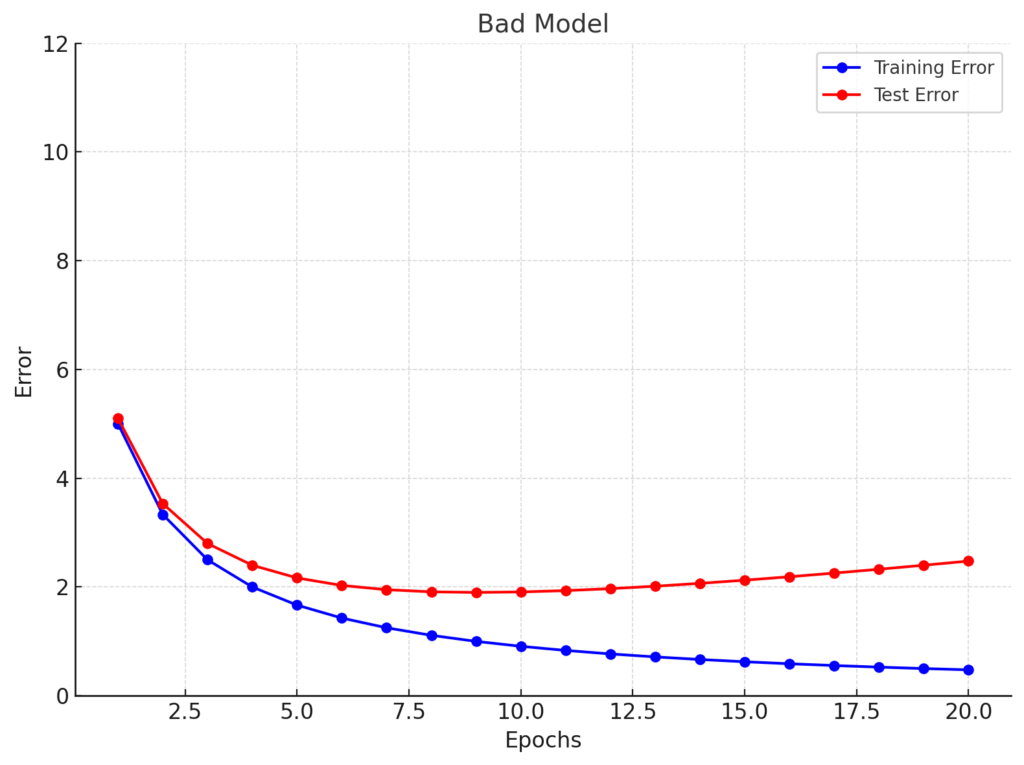
This pattern from the chart above shows that the model is performing too well on the training data while failing to generalize to new data.
So, what does an underfitting model or behavior look like over time?
If a model is underfitting, the error remains high throughout the training process. This indicates the model is too simple to learn, as its error remains consistently high throughout the training process. The model is too simple to learn from the data.
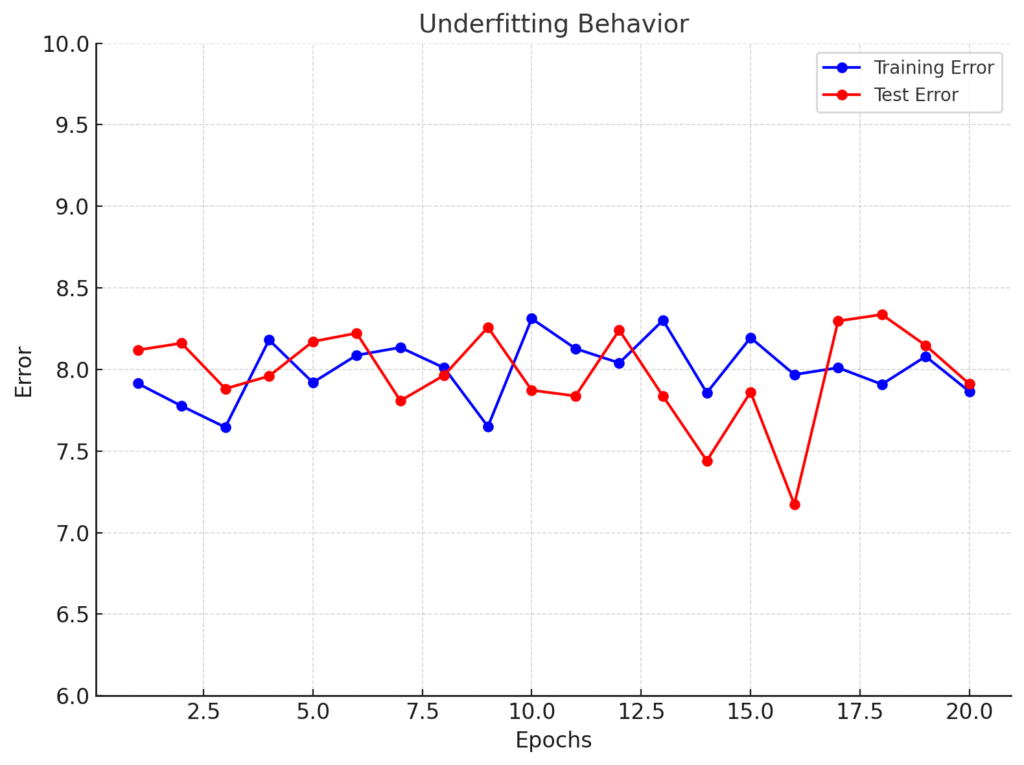
As you can see that the chart above shows how a model that is too simple, fails to learn from the data. Both training and test errors remain consistently high across all epochs, indicating that the model is unable to capture meaningful patterns in the dataset.
Comparing Training and Test Set Performance
Here is a tip to detect underfitting or overfitting in machine learning. You can ompare the performance on the training and test sets.
- Overfitting Performance: An overfitting model performs well on the training set but struggles with test data. As the test error increases, training error decreases.
- Underfitting Performance: An underfitting model performs poorly on both training and test sets. Its inability to learn leads to high errors.
When the model is performing well, both training and test errors decrease over time. The behavior of both sets is similar, showing that the model can detect patterns well.
For example:
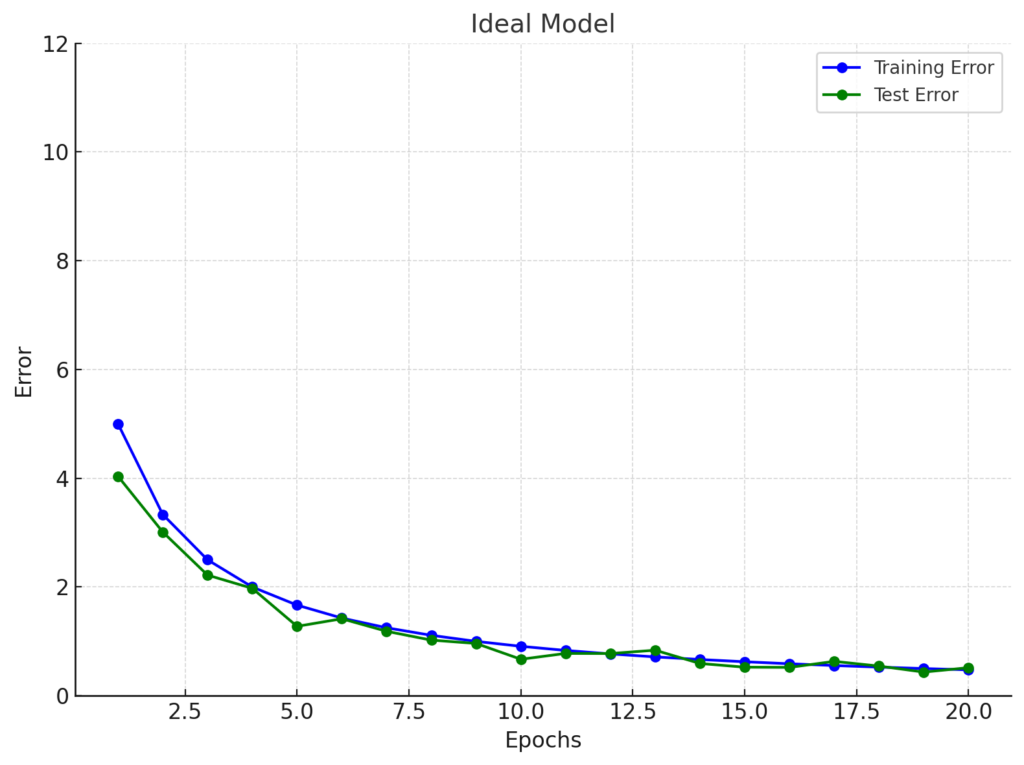
From the chart above, we can see that the similarity in behavior between the two sets indicates that the model is doing well, maintaining consistent performance on both training and unseen data
The Cut-off Point for Overfitting in Machine Learning
The cut-off point, as I like to call it the ‘sweet spot’ to prevent overfitting. In other words, it is important to find that right point to stop training. You can plot the errors for both training and test sets over time and continue to observe their behavior.
The key here is to monitor when the test error begins to increase, as the training error continues to decrease.
On the next chart, you can see the point where the training error continues to decrease, but the test error begins to rise:
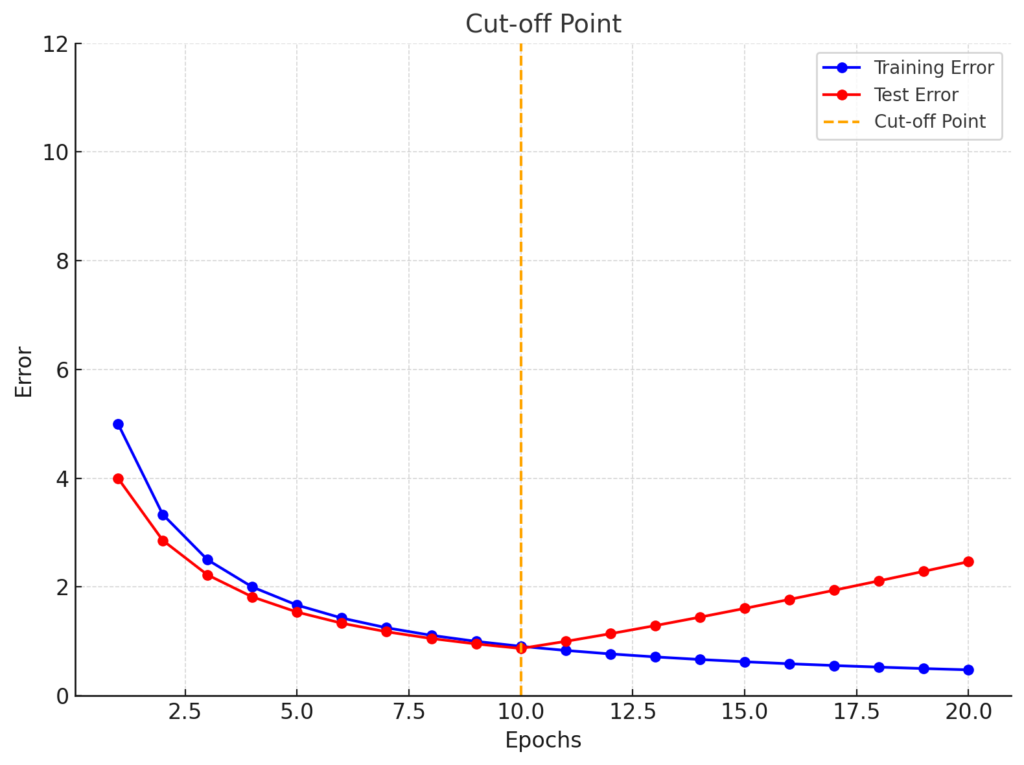
Our chart shows that continuing to further train our data will only result in overfitting, thus reducing the model’s efficiency to find patterns in unseen data.
Conclusion
Nailing the balance between overfitting and underfitting in machine learning is the secret to building models that actually work.
Remember, overfitting in machine learning occurs when your model becomes too focused on the training data, capturing even the noise. It actually turns your model into “know-it-all” that fails when faced with new datasets. And underfitting occurs when your model oversimplifies the problem and misses important patterns. I could say that underfitting models are just plain stupid in a way. They are clueless and end up missing the big picture altogether.
You may like:
- Neural Network and Deep Learning Foundation – Introduction to Neural Network
- TensorFlow in Python: How to Create Tensors
I would love to hear your thoughts on preventing overfitting and underfitting. What methods can you think of to prevent this from happening in your projects?